AI's Little Secret: We've Been Doing Testing All Along
A talk at QonfX Berlin on how traditional testing practices are converging with AI evals — and why the two disciplines have more in common than either side realises.
Blog
Long-form essays and practical notes from real projects in machine learning and product execution.

A talk at QonfX Berlin on how traditional testing practices are converging with AI evals — and why the two disciplines have more in common than either side realises.
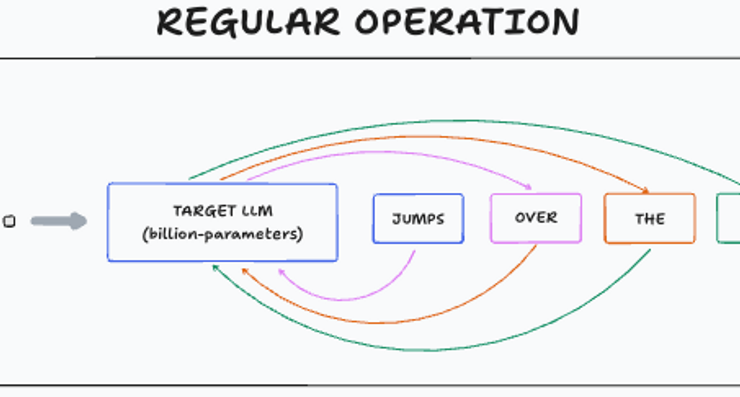
A practical explanation of why speculative decoding speeds up generation in large language models.
A practical read on general-purpose AI definitions and why regulatory clarity matters.

How generative systems can act like a production line for creative assets, with humans in the loop.

From task-specific agents to general intelligence: practical reflections on hardware, software, and AI assistants.

A decade-long perspective on how text classification evolved from lexicon methods to LLM prompting.

Reflections on using LLMs in healthcare conversations and the future of personal digital assistants.

How Spark and Pandas handle One Hot Encoding differently — dense vs. sparse representation — and a practical workaround for interoperability.

A first-hand account of attending TechCrunch Disrupt Berlin 2017, building a WhatsApp chat assistant overnight, bombing the demo, and somehow ending up featured on TechCrunch.

A walkthrough of the common recruitment process steps I've observed for data science teams, from resume screening through face-to-face interviews.

Key parameters for evaluating candidates when building a data science team, from educational qualifications and projects to communication and attitude.